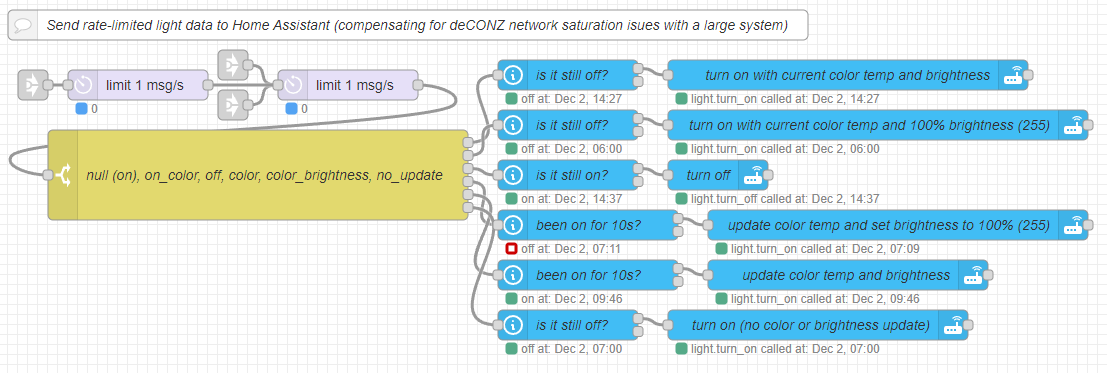
Here’s another chunk of errors/notifications that might be related?
12:29:48:006 failed to add task 377217 type: 6, too many tasks,
12:29:48:006 5 running tasks, wait,
12:29:48:006 failed to add task 377220 type: 11, too many tasks,
12:29:48:006 failed to add task 377221 type: 6, too many tasks,
12:29:48:007 5 running tasks, wait,
12:29:48:028 5 running tasks, wait,
12:29:48:129 5 running tasks, wait,
12:29:48:185 0x001788010BBD4E8D force poll (2),
12:29:48:229 5 running tasks, wait,
12:29:48:329 5 running tasks, wait,
12:29:48:429 5 running tasks, wait,
12:29:48:529 5 running tasks, wait,
12:29:48:611 delay sending request 168 dt 1 ms to 0x001788010BBD4E8D, ep: 0x0B cluster: 0x0300 onAir: 1,
12:29:48:622 delay sending request 168 dt 1 ms to 0x001788010BBD4E8D, ep: 0x0B cluster: 0x0300 onAir: 1,
12:29:48:623 delayed group sending,
12:29:48:625 delay sending request 168 dt 1 ms to 0x001788010BBD4E8D, ep: 0x0B cluster: 0x0300 onAir: 1,
12:29:48:626 delayed group sending,
12:29:48:626 delayed group sending,
12:29:48:629 5 running tasks, wait,
12:29:48:729 5 running tasks, wait,
12:29:48:778 0x0000000000000000 error APSDE-DATA.confirm: 0xE1 on task,
12:29:48:778 delay sending request 168 dt 1 ms to 0x001788010BBD4E8D, ep: 0x0B cluster: 0x0300 onAir: 1,
12:29:48:829 5 running tasks, wait,
12:29:48:872 delay sending request 168 dt 1 ms to 0x001788010BBD4E8D, ep: 0x0B cluster: 0x0300 onAir: 1,
12:29:48:929 5 running tasks, wait,
12:29:48:972 0x0000000000000000 error APSDE-DATA.confirm: 0xE1 on task,
12:29:48:974 delay sending request 168 dt 1 ms to 0x001788010BBD4E8D, ep: 0x0B cluster: 0x0300 onAir: 1,
12:29:49:029 5 running tasks, wait,
12:29:49:129 5 running tasks, wait,
12:29:49:229 5 running tasks, wait,
12:29:49:329 5 running tasks, wait,
12:29:49:370 delay sending request 168 dt 1 ms to 0x001788010BBD4E8D, ep: 0x0B cluster: 0x0300 onAir: 1,
12:29:49:429 5 running tasks, wait,
12:29:49:440 delay sending request 168 dt 1 ms to 0x001788010BBD4E8D, ep: 0x0B cluster: 0x0300 onAir: 1,
12:29:49:529 5 running tasks, wait,
12:29:49:598 delay sending request 168 dt 2 ms to 0x001788010BBD4E8D, ep: 0x0B cluster: 0x0300 onAir: 1,
12:29:49:629 5 running tasks, wait,
12:29:49:658 delay sending request 168 dt 2 ms to 0x001788010BBD4E8D, ep: 0x0B cluster: 0x0300 onAir: 1,
12:29:49:706 delay sending request 168 dt 2 ms to 0x001788010BBD4E8D, ep: 0x0B cluster: 0x0300 onAir: 1,
12:29:49:729 5 running tasks, wait,
12:29:49:787 0x0000000000000000 error APSDE-DATA.confirm: 0xE1 on task,
12:29:49:791 delay sending request 168 dt 2 ms to 0x001788010BBD4E8D, ep: 0x0B cluster: 0x0300 onAir: 1,
12:29:49:829 5 running tasks, wait,
12:29:49:929 5 running tasks, wait,
12:29:49:953 0x0000000000000000 error APSDE-DATA.confirm: 0xE1 on task,
12:29:49:954 delay sending request 168 dt 2 ms to 0x001788010BBD4E8D, ep: 0x0B cluster: 0x0300 onAir: 1,
12:29:50:031 5 running tasks, wait,
12:29:50:070 delay sending request 168 dt 2 ms to 0x001788010BBD4E8D, ep: 0x0B cluster: 0x0300 onAir: 1,
12:29:50:129 5 running tasks, wait,
12:29:50:164 delay sending request 168 dt 2 ms to 0x001788010BBD4E8D, ep: 0x0B cluster: 0x0300 onAir: 1,
12:29:50:230 5 running tasks, wait,
12:29:50:262 delay sending request 168 dt 2 ms to 0x001788010BBD4E8D, ep: 0x0B cluster: 0x0300 onAir: 1,
12:29:50:325 delay sending request 168 dt 2 ms to 0x001788010BBD4E8D, ep: 0x0B cluster: 0x0300 onAir: 1,
12:29:50:329 5 running tasks, wait,
12:29:50:410 delay sending request 168 dt 2 ms to 0x001788010BBD4E8D, ep: 0x0B cluster: 0x0300 onAir: 1,
12:29:50:429 delay sending request 168 dt 2 ms to 0x001788010BBD4E8D, ep: 0x0B cluster: 0x0300 onAir: 1,
12:29:50:529 delay sending request 168 dt 3 ms to 0x001788010BBD4E8D, ep: 0x0B cluster: 0x0300 onAir: 1,
12:29:50:621 delay sending request 168 dt 3 ms to 0x001788010BBD4E8D, ep: 0x0B cluster: 0x0300 onAir: 1,
12:29:50:629 delay sending request 168 dt 3 ms to 0x001788010BBD4E8D, ep: 0x0B cluster: 0x0300 onAir: 1,
12:29:50:672 0x00178801097845F4 error APSDE-DATA.confirm: 0xE9 on task,
12:29:50:673 delay sending request 168 dt 3 ms to 0x001788010BBD4E8D, ep: 0x0B cluster: 0x0300 onAir: 1,
12:29:50:730 delay sending request 168 dt 3 ms to 0x001788010BBD4E8D, ep: 0x0B cluster: 0x0300 onAir: 1,
12:29:50:829 delay sending request 168 dt 3 ms to 0x001788010BBD4E8D, ep: 0x0B cluster: 0x0300 onAir: 1,
12:29:50:929 delay sending request 168 dt 3 ms to 0x001788010BBD4E8D, ep: 0x0B cluster: 0x0300 onAir: 1,
12:29:51:029 delay sending request 168 dt 3 ms to 0x001788010BBD4E8D, ep: 0x0B cluster: 0x0300 onAir: 1,
12:29:51:068 delay sending request 168 dt 3 ms to 0x001788010BBD4E8D, ep: 0x0B cluster: 0x0300 onAir: 1,
12:29:51:105 delay sending request 168 dt 3 ms to 0x001788010BBD4E8D, ep: 0x0B cluster: 0x0300 onAir: 1,
12:29:51:129 delay sending request 168 dt 3 ms to 0x001788010BBD4E8D, ep: 0x0B cluster: 0x0300 onAir: 1,
12:29:51:229 delay sending request 168 dt 3 ms to 0x001788010BBD4E8D, ep: 0x0B cluster: 0x0300 onAir: 1,
12:29:51:329 delay sending request 168 dt 3 ms to 0x001788010BBD4E8D, ep: 0x0B cluster: 0x0300 onAir: 1,
12:29:51:429 delay sending request 168 dt 3 ms to 0x001788010BBD4E8D, ep: 0x0B cluster: 0x0300 onAir: 1,
12:29:51:538 delay sending request 168 dt 4 ms to 0x001788010BBD4E8D, ep: 0x0B cluster: 0x0300 onAir: 1,
12:29:51:629 delay sending request 168 dt 4 ms to 0x001788010BBD4E8D, ep: 0x0B cluster: 0x0300 onAir: 1,
12:29:51:651 0x0017880106968FBD error APSDE-DATA.confirm: 0xE9 on task,
12:29:51:652 delay sending request 168 dt 4 ms to 0x001788010BBD4E8D, ep: 0x0B cluster: 0x0300 onAir: 1,
12:29:51:729 delay sending request 168 dt 4 ms to 0x001788010BBD4E8D, ep: 0x0B cluster: 0x0300 onAir: 1,
12:29:51:825 0x001788010BBD4E8D force poll (2),
12:29:51:969 0x001788010BBD4E8D force poll (2),
12:29:55:494 delayed group sending,
12:29:55:495 delayed group sending,
12:29:55:495 delayed group sending,
12:29:55:495 delayed group sending,
12:29:55:495 delayed group sending,
12:29:55:495 delayed group sending,
12:29:55:495 delayed group sending,
12:29:55:496 delayed group sending,
12:29:55:496 delayed group sending,
12:29:55:496 delayed group sending,
12:29:55:496 delayed group sending,
12:29:55:496 delayed group sending,
12:29:55:729 5 running tasks, wait,
12:29:55:829 5 running tasks, wait,
12:29:55:929 5 running tasks, wait,
12:29:56:030 5 running tasks, wait,
12:29:56:088 0x0000000000000000 error APSDE-DATA.confirm: 0xE1 on task,
12:29:56:129 5 running tasks, wait,
12:29:56:229 5 running tasks, wait,
12:29:56:339 0x0000000000000000 error APSDE-DATA.confirm: 0xE1 on task,
12:29:57:037 0x00178801060959B4 error APSDE-DATA.confirm: 0xE9 on task,
12:29:59:902 reuse dead link (dead link container size now 394)
And a reminder if @manup or others don’t remember - I’m the guy with the big system: 368 nodes (1 ConBee II, 17 FLS-CT strip controllers, and 350 Hue bulbs) as well as 106 groups.